Domain Driven Architecture
dda-pallet series: 3-Convention over Configuration
Tags: dda-managedvm-crate, howto, Convention over Configuration, clojure ide, composition, dda-pallet, phases
Our goal is a development environment properly set up straight away from the beginning - and additionally to be able to adjust your setup as you like. We are using dda-pallet to describe this infrastructure as clojure code. This blog is part of the "dda-pallet" series and will show step by step how to setup a clojure IDE:
- Provision existing Targets
- Compose crates
- Convention over Configuration with Domain Driven Design.
- Execute Pallet local
- Plugin Operational Services
- Test-driven DevOps
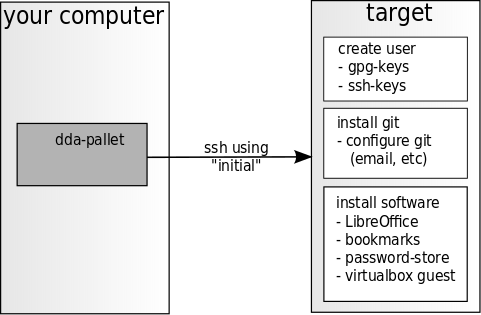
Last time we cloned some git repositories into a created user home in our future IDE. Today we will proceed with the dda-managed-vm crate.
You can think of the dda-managed-vm as a base-vm already having some basic tools installed, like bookmarks, password-store, gpg keys, mail, LibreOffice, etc. But we will also find some more fine grained installations & configurations:
- We will configure the user to be installed with our credentials. (Definitions of gpg- or ssh-keys are optional, so that you will not be forced to expose your credentials to an unsafe target system):
- user name,
- password,
- ssh-key and
- gpg keys
- configured bookmarks
- a ready-to-use team-password-store and
- a bunch of useful background tools installed, like virtualbox-guest-utils and io-/if-/h-top tools for vm analysis
While applying the dda-managed-vm we will learn how Domain Driven Design fits into the functional DevOps world and why the separation of domain and infrastructure is important - even for infrastructure code.
As a result we should be able to log in to our virtual machine and be able to do various tasks like browsing the internet (for safety reasons using a vm for browsing the internet might be a good idea), use LibreOffice, password-store, GPG and many more. And we will be able to recreate our ready-to-use vm, whenever we want ...
Preconditions
We have the same preconditions as last time. We will start from a clean virtual machine having xubuntu 16.4.2LTS and ssh-server installed. You can find a more detailed description on how to create a vm in the first post of this series. Keep the used credentials in your mind for first time provisioning.
Get dda-managed-vm
Let's start and clone the dda-managed-vm:
- Clone dda-managed-vm repository from GitHub:
git clone -b dda-managed-vm-0.4.0 https://github.com/DomainDrivenArchitecture/dda-managed-vm.git
Detailed Configuration
For your context, we use the following configuration schema defined in external_config.clj:
(def ExternalConfigSchema
{:provisioning {:ip s/Str
:login s/Str
:password s/Str}
:user {:name s/Str
:password s/Str
:email s/Str
(s/optional-key :ssh) {:ssh-pub-key s/Str
:ssh-prvate-key s/Str}
(s/optional-key :gpg) {:gpg-public-key s/Str
:gpg-private-key s/Str
:gpg-passphrase s/Str}}})
Now let's put your informations into the configuration file:
- Open "user-config.edn" in the repositories root folder:
./dda-managed-vm/user-config.edn - Adjust your target ip (you can use the command
ifconfigon the remote virtual machine to find the IP - in our case it is 192.168.56.104) in the line::ip "192.168.56.104" - Fill in your provision user credentials of the remote machine (if you have chosen the same credentials in the vm-setup as we did, go with "initial - secure1234". If not, replace them with yours) in the lines:
:login "initial" :password "secure1234" - Adjust name and password for the user we will create. The password is given unhashed:
:name "test-user" :password "xxx" - Adjust the email, if you want to use git (or for test purposes you may keep the preconfigured dummy email) :
:email "test-user@mydomain.org" - (Optional) Configure your authorized-keys for the new user in order be able to connect by ssh and/or to use GPG. If you don't need them, you can leave the preconfigured snakeoil keys:
:ssh {:ssh-pub-key "rsa-ssh kfjri5r8irohgn...test.key comment" :ssh-prvate-key "123Test"} :gpg {:gpg-public-key "-----BEGIN PGP PUBLIC KEY BLOCK----- ..." :gpg-private-key "-----BEGIN PGP PUBLIC KEY BLOCK----- ..." :gpg-passphrase "passphrase"}
Provision your Virtual Machine
Now it's time to bring our configuration to our virtual machine:
- Start your REPL & switch to the instantiate-existing namespace
(use 'dda.pallet.dda-managed-vm.app.instantiate-existing) - Start provisioning
Your REPL should look somewhat as follows:(apply-install)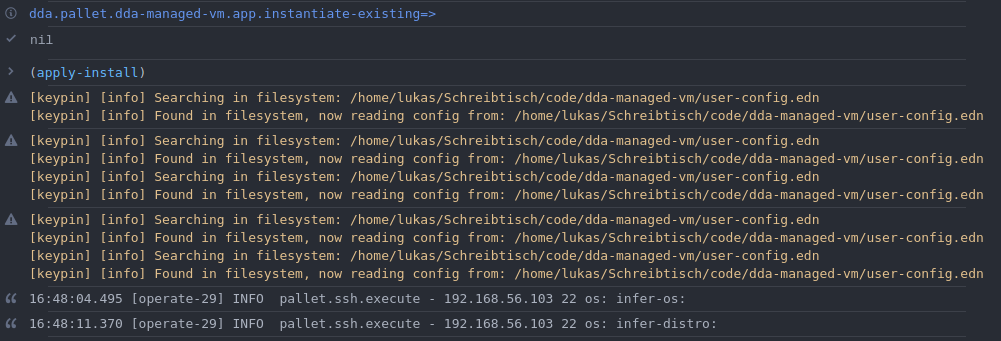 In case of success, your REPL will finally show:
In case of success, your REPL will finally show: 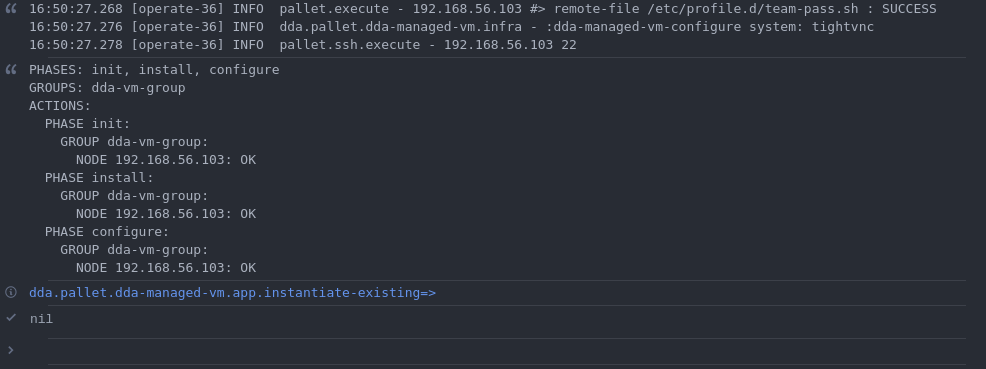
- We finished provisioning successfully. So let's test the newly provisioned vm. After a reboot you can log on as "test-user" (or with the user you specified in the configuration) and enjoy all the useful software you just installed on the virtual machine:
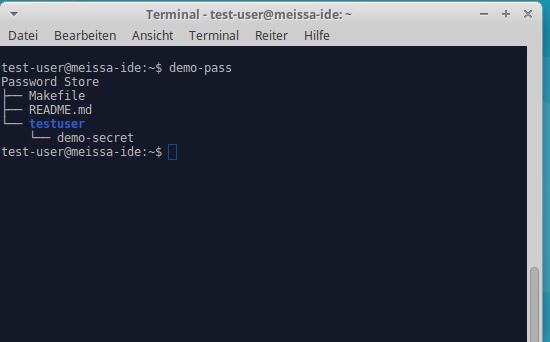 The content of password store.
The content of password store. 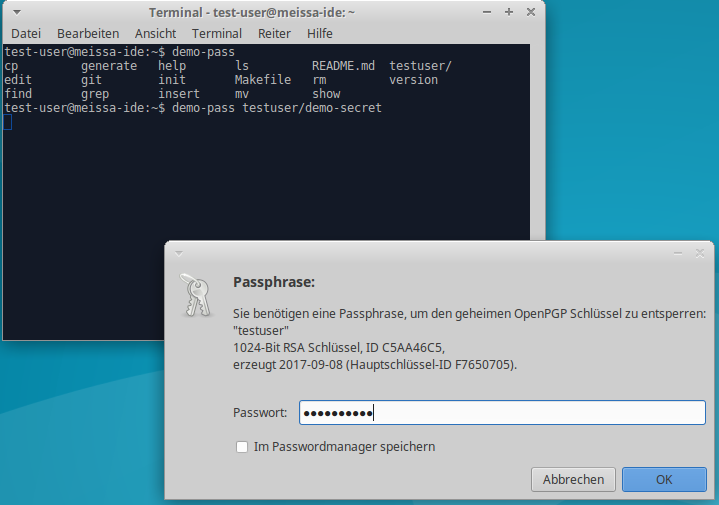 Decrypt a secret.
Decrypt a secret. 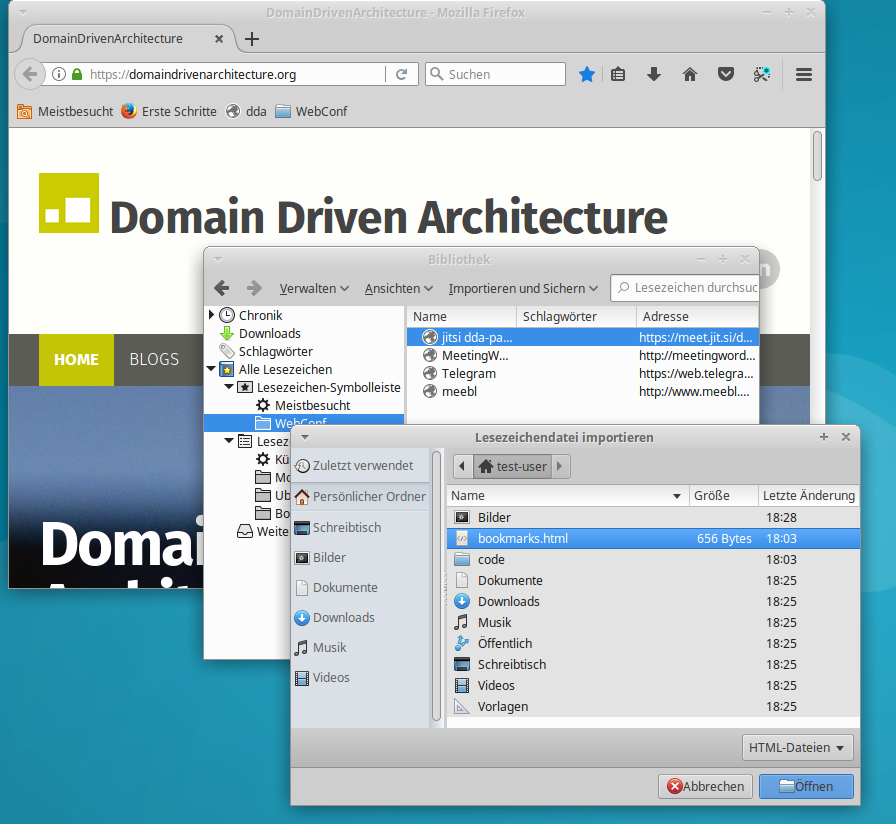 Import bookmarks in your browser.
Import bookmarks in your browser. - Inspect Logfiles: If the worst comes to the worst it my be a good idea to know, where logfiles are configured and stored. Logfiles are stored under your REPLs execution location in
The log-level configuration you will find at:./logs/pallet.logdev-resources/logback.xml
Domain Driven Design for DevOps
Domain Driven Design is quite important in object oriented application development. But why should Domain Driven Design be important in a DevOps world?
Let's think about what's cool and uncool:
- Having a simple and compact configuration like our
user-config.ednis cool, I think. The DevOps user will be able to easily use our components without being forced to dive deeply into ugly details (like the fact that virtual-box-guest utils are breaking xubuntu x-server since 16.04.02 ...). - Being forced to clone our ddaArchitecture documentation repository into a code subdir, whenever you are creating a managed vm, you may consider as uncool in general. On the other hand we assume this convention will be a good idea to the dda-pallet community.
- Being able to synergize with a worldwide community on the infra level would be cool.
- Being able to define own conventions easily would be cool.
This thoughts lead us to the idea to strictly separate conventions (we call it domain) from low-level configurations (we call it infra). Both levels are represented through a data-driven API. And this way dda-pallet offers the best of both worlds: the convenience of an easy-to-use domain-level containing conventions e.g. for file locations, as well as the power of an infra-level, which allows you to adjust all kinds of configuration details in case of special or different needs.
Doing so we enable synergy in building an infra-level abstraction together with a world-wide community. The structure of Linux software will be similar enough across companies and countries.
On the domain-level everyone is free to implement his own abstractions and conventions. The domain layer transforms compact configuration data into large infra configuration data. As domain level is pure data transformation, modifying our predefined conventions or develop on your own will be an easy thing to do. Test driven development is one of our architecture goals, in the domain layer unit-tests are easy to implement.
Find Domain Driven Design parts in the code
You can find all these ideas in our code:
- domain / infra-layer: You will find in every crate infra and domain namespaces representing a layer.
- infra ns translates the broad infra configuration into action executed on target nodes. Infra configuration is organized along the typical Linux package structures.
- domain ns transforms compact convention containing configuration to broad infra configuration.
- app ns binds domain and infra together and composes other crates.
- boundaries: infra, domain and app namespaces are intended to be used from outside. So every input and output will be validated here.
- schema: At the moment we are expressing our configurations using plumatic schema. In future we may switch to clojures new spec.



